线性回归算法深入理解
线性回归算法就是已知样本分布,选择合适的曲线对样本进行拟合,然后用拟合曲线预测新的样本。
假设坐标系中有三点 (1,2),(3,1),(3,3),如图 1 所示:
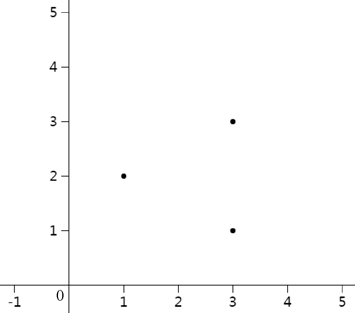
图1:坐标系中三点
我们的目的是找到一条经过点(0,0)的直线去拟合它们。如果不使用数学工具,直接用手画的话,很容易获得这样的直线,如图 2 所示。图 2 中的曲线最大程度上拟合了这 3 个点。那么如何用数学方法获得这个直线呢?
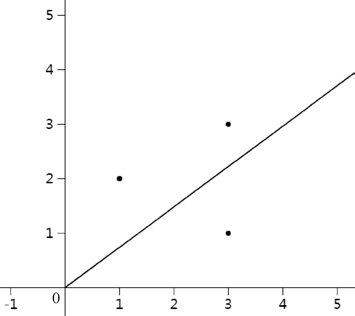
图2:手画拟合直线
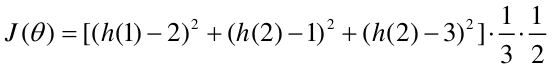
上式中括号里面计算的是我们假设函数到真实值的距离,1/3 用于求平均值,1/2 为了方便推导添加的系数。我们将公式 h(x) 代入公式 J(θ) 中,化简后公式推导可得:
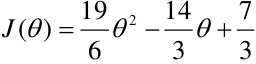
这是一个二次函数,所以可以用梯度下降的方法求得其最小值。
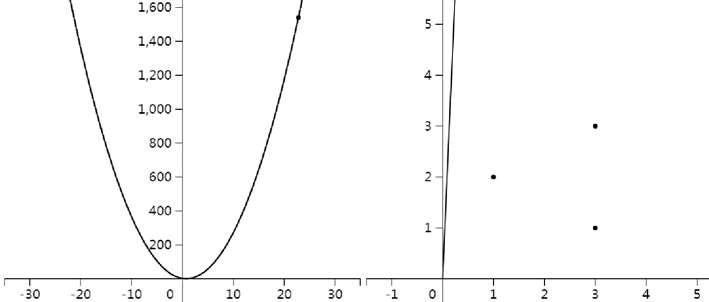
图3:初始化直线
设置学习速率 α=0.01,如图 4 所示,直线初始化位置 h(x)=22.78x,图 4 中的右图记录了每次迭代直线的位置。迭代 124 次后得到了最优的直线。迭代过程的具体数据如表 4 所示。
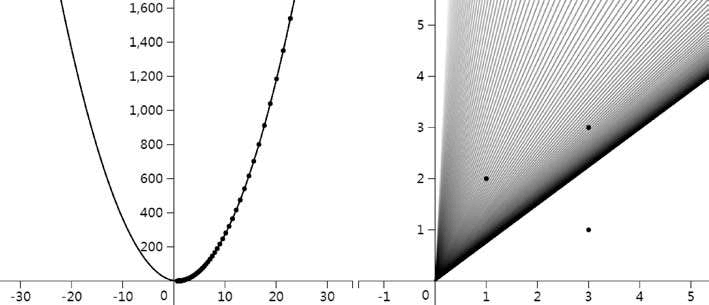
图4:梯度下降法求最优曲线
直线与损失函数之间的关系:
图6:直线与损失函数之间的关系
至此,我们通过梯度下降方法求解了机器学习中的一个重要问题——线性回归。您是否已经通过这个过程理解了“机器学习”中“学习”的意思了呢?在求解最优直线过程中,我们随机假设一条直线,然后获得它与最优解的距离(差距),找到最优解的方向(曲线斜率),然后按照这个方向以一定步长(学习速率α)不断地移动(学习过程),最终得到最优解。这就是“机器学习”中的“学习”。
这是因为我们所举的例子中只有一个参数 θ,而在现实应用中可能有 n 个参数 θ,随着 θ 数量的增加,导数求解方法的复杂度会急剧上升,计算的性能会下降。这时梯度下降的优势就展现出来了,即使在面对高维空间求解(多个参数θ)时,梯度下降的计算性能也会很好。
迭代次数也是决定最终模型好坏的关键因素。在第一次迭代模型的时候可以设置一个比较大的值,然后每次迭代观察系数的变化,根据这些值获得最优的迭代值。一般设置迭代次数为 1000。
假设坐标系中有三点 (1,2),(3,1),(3,3),如图 1 所示:
图1:坐标系中三点
我们的目的是找到一条经过点(0,0)的直线去拟合它们。如果不使用数学工具,直接用手画的话,很容易获得这样的直线,如图 2 所示。图 2 中的曲线最大程度上拟合了这 3 个点。那么如何用数学方法获得这个直线呢?
图2:手画拟合直线
1. 数学角度解释回归曲线
以上面的假设为例,用数学的思想描述回归曲线就是,要找到一条过 0 点的直线,使得 3 个点到这条直线的距离最小。首先将这条直线表示为:h(x)=θ⋅x
问题再次简化,我们只需要找到最合适的 θ,使得 3 个点到直线距离最小。计算损失函数,即计算 3 个点到直线的距离:2. 梯度下降法求解最优直线
先随机初始化一条直线(见图 3):h(x)=22.78x
它的损失函数:图3:初始化直线
图4:梯度下降法求最优曲线
图6:直线与损失函数之间的关系
3. 导数求解与梯度下降
为什么在得到损失函数 J(θ) 后不直接令 J(θ)=0 而求得最优的参数呢?如果这样则只需要一步,且可以获得最优解,而不是像梯度下降方法一样,只能无限接近。这是因为我们所举的例子中只有一个参数 θ,而在现实应用中可能有 n 个参数 θ,随着 θ 数量的增加,导数求解方法的复杂度会急剧上升,计算的性能会下降。这时梯度下降的优势就展现出来了,即使在面对高维空间求解(多个参数θ)时,梯度下降的计算性能也会很好。
4. 设置学习速率α与迭代次数
学习速率 α 与迭代次数设置的具体情况应该看具体的模型以及损失函数。在实际应用中我们可以打印出每一次迭代的所有数据,与图 4 的的情况比对,从而得出最优的学习速率 α。一般情况下,取 α=0.001。迭代次数也是决定最终模型好坏的关键因素。在第一次迭代模型的时候可以设置一个比较大的值,然后每次迭代观察系数的变化,根据这些值获得最优的迭代值。一般设置迭代次数为 1000。