Python kubernetes库的使用
我们介绍的工具叫作 kubernetes-client。这个软件包是 kubernetes 团队提供的,更新速度还是不错的。其他类似的开发包也有一些,它们提供各自不同风格的接口,但是我们这里不打算介绍,仅仅关注 kubernetes-client 这个软件包。
由于 kubernetes 涉及的概念和内容非常多,一些基础的知识这里就直接跳过了,例如如何搭建一个kubernetes集群,如何设置集群用户等,所以本节内容适合有一定 kubernetes 操作经验的人阅读。
kubernetes-client 是一个需要自行安装的软件包,推荐的安装方法还是使用 PIP 命令。命令如下:
pip install kubernetes
在使用之前我们需要知道被操作集群的信息,它在 kubernetes 中用一个 yaml 文件表示。下面的例子显示的便是一个集群信息文件。kubernetes 目前的版本是 10.0.0。
apiVersion: v1
kind: Config # 表明这是一个配置文件
clusters:
- name: "demo1" # 集群的名字
cluster:
server: https://lovepython/k8s/clusters/c-zjhdk # 集群的地址
api-version: v1
certificate-authority-data: # 集群的证书
"LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUM3akNDQ\
WRhZ0F3SUJBZ0lCQURBTkJna3Foa2lHOXcwQkFRc0ZBREFvTV\
JJd0VBWURWUVFLRXdsMGFHVXQKY\
21GdVkyZ3hFakFRQmdOVkJBTVRDV05oZEhSc1pTMWpZVEFlRncwe\
E9UQXlNVFV3TkRBNE16TmFGd\
zB5T1RBeQpNVEl3TkRBNE16TmFNQ2d4RWpBUUJnTlZCQW9UQ1h\
Sb1pTMXlZVzVqYURFU01CQUdBM\
VVFQXhNSlkyRjBkR3hsCkxXTmhNSUlCSWpBTkJna3Foa2lHOXcw\
QkFRRUZBQU9DQVE4QU1JSUJDZ\
0tDQVFFQTkwNjNXekVWVmgvNzBsWisKb2NpQ1haZHFXNWkwbHN6W\
m5PUUF6NWh1VDNadDlWamx0R\
S9zQkllUTBjYnhZQlZDOWFqR01zM3RwOFk1WjJPWQpUbTZtNzlQ\
QjlpaC9DUDZPb0FIQy9JbDRMZ\
09zSTVvK1ErN0ZydVFHenA5c3JnMWV4ZkEzQVlqRmROK21mWE\
ptCmhxdEZMYzV5VDRwZ1U5VElMd\
U9kU0N2ZFRaTXl2b2wySG82MWVsRjYzdEdrdEpya2M4MXBHaXRhbU\
1GblhqRUEKMHkrZFpvdlJwS\
HNMdlgxUEtESmY1VWsydUVkUDExbzEwdEJYcnlPNy9mZEsvREJleWF\
2UFB2K05uV1VremtKWQp3d\
DV2TkIzUUZrNEwvRjd6MUZkNUdERXdWYjdZK1lwODcxU0lyWCtqUXdTT\
2dpVFk3T1JvTldSVm1MY\
m9Cd1hUCkVEazcyUUlEQVFBQm95TXdJVEFPQmdOVkhROEJBZjhF\
QkFNQ0FxUXdEd1lEVlIwVEFRS\
C9CQVV3QXdFQi96QU4KQmdrcWhraUc5dzBCQVFzRkFBT0NBUUV\
BeHAzUTNJR01uK0hLaHc4ZkVua\
3Q5TjNxRUFjdjZYTVczN2c4OWJ4MgpPdWxIQkxVcDFpYjdsYXBBanJnd\
VN6NEhlM2prL1R2SHIxZ\
0JiSTNzSHZZVi9NcU9LbGdzdG51T0NyeGEyWlNRCkM1SnZsL01\
aMzc2OXBQZnkwMmRaVnpKMERNL\
3JOK3RaUDdRRWo0VnpVRzIyWDhxM3dTQTF5ckpQSitETUxvZ\
GsKajZUNGZvR1ppa25nRGh0RlY0Y\
2dtbjVZYThiaUlpYlVNVi9mMDlJVUNGUm82aU5kZjVGNG5vTU9XWE\
hSYi9ZRApTemJjTXliMGV0e\
lpXWS82ckNoUWtHUWk4ZlBjeFV0dG5VTFhLdG5WNEpROGFDZUtiN\
FJpZmt5QzFqQ1BtUFFJCm1vQ\
TJJcXhSVVVsNTFHaXRXL0hCbFpXR2hpL1YwM0xWYi9VTWttOXFqc\
G1adUE9PQotLS0tLUVORCBDR\
46 VJUSUZJQ0FURS0tLS0t"
users: # 用户信息
- name: "user-xckkr" # 用户名
user: # 用户密码信息
token: "kubeconfig-user-xckkr:9xb86js8htrcbw2j2nr2qglqvtc9rh4wrtqd\
fpvchcz7wvf58dwpns"
contexts:
- name: "voddev"
context:
user: "user-xckkr"
cluster: "demo1"
current-context: "demo1"
首先需要设定环境变量 KUBECONFIG,让其指向该配置文件。这个用法和 kubectrl 命令行工具是一样的。然后就可以运行后面例子的代码了。第一个例子是查看当前集群所有的 pod 信息。
pod 是一个比容器大一点的概念,是在 kubernetes 中的最小调度单位。在 kubernetes 中不能说启动一个容器实例,只能说启动一个 pod。一个 pod 可以包含一个或者几个容器,这些容器的 IP 地址一样,如果需要对外提供服务,只能用不同的端口或不同的传输层类型来区分;同一个 pod 中的容器运行在同一台主机(node)上。
图 1 描述了node、pod 和容器之间的关系。一个 node 上可以运行多个 pod,一个 pod也 可以包含多个容器,这些容器共享一个 IP 地址和其他资源。
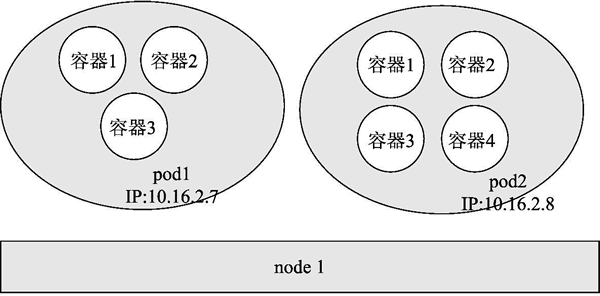
图 1 node、pod和容器的关系
kubernetes 集群本身也有一些系统pod在运行,这些容器主要完成集群的管理工作。下面是完整的代码。
from kubernetes import client, config # 引入我们要用的包
def query_pod(): # 定义我们的主函数
config.load_kube_config() # 读入集群相关信息,就是要操作哪个集群
v1 = client.CoreV1Api() # 得到客户端中的一个组接口
# 查询所有的pod信息
ret = v1.list_pod_for_all_namespaces(watch=False)
for i in ret.items: # 遍历得到的pod
print("%s\t%s\t%s" % # 显示pod的IP地址、所属命名空间和名字
(i.status.pod_ip, i.metadata.namespace, i.metadata.name))
if __name__ == '__main__': # 作为脚本时运行
query_pod () # 运行主程序
运行后的输出结果如下:
$ python3 demo1.py
Listing pods with their IPs: # 分为三列,IP地址、命名空间和名字
10.42.0.6 cattle-system cattle-cluster-agent-56cd4f89c5-jckdr
10.89.8.130 cattle-system cattle-node-agent-7z88g
10.89.24.174 cattle-system cattle-node-agent-kzb5s
10.89.24.41 cattle-system cattle-node-agent-qt2f2
10.89.25.251 cattle-system cattle-node-agent-wmpst
......
在前面的例子中,我们有很多的 pod 都是在 default 这个命名空间中。另外,有些 kubernetes 的管理 pod 都在 kube-system 这个命名空间中。
在 kubernetes 中定义了很多事件,如某个 pod 被创建了、某个 pod 被重新部署了等。我们也可以通过代码监视这些事件。下面是一个例子。
from kubernetes import client, config, watch
def event_demo ():
config.load_kube_config() # 得到集群信息
v1 = client.CoreV1Api() # 得到接口实例
count = 10 # 读取10个事件
w = watch.Watch() # 创建一个监视对象
for event in w.stream(v1.list_namespace, timeout_seconds=10):
print("Event: %s %s" % (event['type'], event['object'].
metadata.name))
count -= 1 # 打印事件的类型和名字
if not count: # 如果检测到足够数量的事件,退出循环
w.stop()
print("Ended.") # 退出循环
if __name__ == '__main__':
event_demo()
运行后的输入结果如下:
$ python3 demo2.py
Event: ADDED kube-public
Event: ADDED kube-system
Event: ADDED cattle-system
Event: ADDED default
Event: ADDED ingress-nginx
Ended.
kubernetes 的升级速度很快,所以接口的版本也比较多。我们可以通过查询的方式得到某个集群支持的接口版本和推荐的版本。示例如下:
from kubernetes import client, config
def query_api_ver ():
config.load_kube_config() # 得到集群信息
print("Supported APIs (* is preferred version):")
print("%-20s %s" % # 打印版本信息
("core", ",".join(client.CoreApi().get_api_versions().versions)))
for api in client.ApisApi().get_api_versions().groups:
versions = []
for v in api.versions:
name = ""
if v.version == api.preferred_version.version and len(
api.versions) > 1:
name += "*"
name += v.version
versions.append(name)
print("%-40s %s" % (api.name, ",".join(versions)))
if __name__ == '__main__':
query_api_ver()
运行后的输出如下:
$ python3 example3.py
Supported APIs (* is preferred version): # 包含两列,接口名和版本
core v1
apiregistration.k8s.io *v1,v1beta1
extensions v1beta1
apps *v1,v1beta2,v1beta1
events.k8s.io v1beta1
authentication.k8s.io *v1,v1beta1
authorization.k8s.io *v1,v1beta1
autoscaling *v1,v2beta1
batch *v1,v1beta1
certificates.k8s.io v1beta1
networking.k8s.io v1
policy v1beta1
rbac.authorization.k8s.io *v1,v1beta1
storage.k8s.io *v1,v1beta1
admissionregistration.k8s.io v1beta1
apiextensions.k8s.io v1beta1
scheduling.k8s.io v1beta1
crd.projectcalico.org v1
metrics.k8s.io v1beta1
pod 的数量一方面和运算能力相关,另一方面和资源使用量相关,也和需要支付的费用相关。使用云的一个很大好处就是能够快速改变某个服务的处理能力,而且按需付费。如果使用手工改变 pod 的数目来达到这个目的显然是比较麻烦的。
为了便于管理 pod 的数量,kubernetes 提供了一个 deployment 概念。我们可以指定 deployment 中的 pod 数目。通过调整 pod 的数目,kubernetes 会自动帮你创建新的 pod 以提升计算能力,或者关闭一些 pod 来释放闲置的计算能力并降低费用。
我们只需要提供 deployment 的目标 pod 数目,kubernetes 会根据实际情况自动添加或者关闭一些 pod 来保证实际运行的 pod 数量和期望值一致。可以使用很多种方式定义和修改 deployment,这里使用 yaml 文件部署 deployment。
下面使用 deployment 对象定义文件(格式是 yaml):
apiVersion: extensions/v1beta1 # 接口版本
kind: Deployment # 类型是deployments
metadata: # 名字
name: nginx-deployment-test
spec: # 定义详情
replicas: 3 # 期望3个pods
template: # pods模版
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9 # 使用的容器镜像
ports:
- containerPort: 80
from os import path
from kubernetes import client, config, utils
def create_deployment_via_yaml():
config.load_kube_config()
k8s_client = client.ApiClient()
# 部署yaml文件
utils.create_from_yaml(k8s_client, "nginx-deployment.yaml")
k8s_api = client.ExtensionsV1beta1Api(k8s_client)
deps = k8s_api.read_namespaced_deployment("nginx-deployment", "default")
print("Deployment {0} created".format(deps.metadata.name))
if __name__ == '__main__':
create_deployment_via_yaml ()
运行后输出结果如下:
$ python3 create_deployment_from_yaml.py
Deployment nginx-deployment created
示例如下:
from os import path
import yaml
from kubernetes import client, config
DEPLOYMENT_NAME = "nginx-deployment"
def create_deployment_object(): # 创建deployment的内容
container = client.V1Container( # 容器内容
name="nginx",
image="nginx:1.7.9",
ports=[client.V1ContainerPort(container_port=80)])
template = client.V1PodTemplateSpec( # 模版
metadata=client.V1ObjectMeta(labels={"app": "nginx"}),
spec=client.V1PodSpec(containers=[container]))
spec = client.ExtensionsV1beta1DeploymentSpec( # 详情
replicas=3,
template=template)
deployment = client.ExtensionsV1beta1Deployment(
api_version="extensions/v1beta1",
kind="Deployment",
metadata=client.V1ObjectMeta(name=DEPLOYMENT_NAME),
spec=spec)
return deployment # 返回一个deployment对象
def create_deployment(api_instance, deployment):
api_response = api_instance.create_namespaced_deployment(
body=deployment,
namespace="default")
print("Deployment created. status='%s'" % str(api_response.status))
def update_deployment(api_instance, deployment): # 更新deployments
deployment.spec.template.spec.containers[0].image = "nginx:1.9.1"
api_response = api_instance.patch_namespaced_deployment(
name=DEPLOYMENT_NAME,
namespace="default",
body=deployment)
print("Deployment updated. status='%s'" % str(api_response.status))
def delete_deployment(api_instance): # 删除某个deployments
api_response = api_instance.delete_namespaced_deployment(
name=DEPLOYMENT_NAME,
namespace="default",
body=client.V1DeleteOptions(
propagation_policy='Foreground',
grace_period_seconds=5))
print("Deployment deleted. status='%s'" % str(api_response.status))
def create_deployment_via_api ():
config.load_kube_config()
extensions_v1beta1 = client.ExtensionsV1beta1Api()
deployment = create_deployment_object()
create_deployment(extensions_v1beta1, deployment)
update_deployment(extensions_v1beta1, deployment)
delete_deployment(extensions_v1beta1)
if __name__ == '__main__':
create_deployment_via_api()
运行后的输出结果如下:
$ python3 deployment_examples.py
RequestsDependencyWarning)
Deployment created. status='{'available_replicas': None,
'collision_count': None,
'conditions': None,
'observed_generation': None,
'ready_replicas': None,
'replicas': None,
......
这样做的好处是如果某个容器失效了,系统会自动重启一个来替代它的工作,保证系统的正常运转。这个监视 pod 的状态和重启 pod 的操作都是 kubernetes 自动完成的,不需要人工来干预。