线性回归算法实战:糖尿病患者病情预测
线性回归算法被广泛应用于医学领域。本节我们将通过糖尿病患者的体重,预测糖尿病患者接下来病情发展的情况。在实际应用中,可以根据预测模型,提前预知患者的病情发展,从而提前做好应对措施,改善患者的病情。
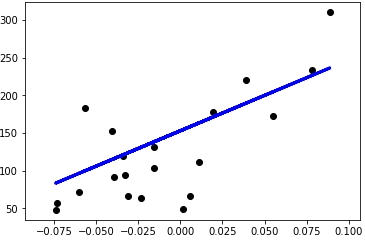
图1:模型拟合曲线
通过模型可以看出,随着体重指标的增加,病情的级数也在增加,因此可以预测某位患者接下来一年内病情将会如何发展。当然,通过多变量分析我们可以得到更好的模型。
1) 导入模块
这里我们用到了 Scikit 库调用模块 sklearn 中的 diabetes 数据集,所以要先导入数据集模块。然后使用线性回归模型,导入linear_model模块。最后对模型进行评估,导入 mean_squared_error,r2_score 模块。In [1]: import matplotlib.pyplot as plt ...: from sklearn import datasets, linear_model ...: from sklearn.metrics import mean_squared_error, r2_score
2) 导入数据集
In [2]: diabetes = datasets.load_diabetes()
3) 观察目标变量
这里我们导入目标变量,并对它的一些信息进行观察。In [3]: y=diabetes['target'] ...: diabetes['target'].min(),diabetes['target'].max(),diabetes['target'].ptp() # 观察目标变量,最小值,最大值,最大值-最小值 Out[3]: (25.0, 346.0, 321.0)
4) 观察体重指标变量
这个模型中,我们主要想通过体重指标来预测目标变量,所以通过 Numpy 的索引方法取得体重的相关数据。In [4]: x = diabetes.data[:,2] # 取体重指标列 ...: x=x.reshape(442,1) # 转置 ...: x.min(),x.max(),x.ptp() # 查看体重指标列最小值,最大值,最大值-最小值 Out[4]: (-0.090275295898518501, 0.17055522598066, 0.26083052187917849)
5) 处理训练集和测试集
分别对因变量和自变量进行分组,通过训练集来训练模型,然后通过测试集评价模型。这里手工取训练集和测试集,sklearn 中也提供了专有方法取训练集和测试集。具体操作参加本网站《sklearn库中文教程》。
In [5]: x_train = x[:-20] # 获得训练集因变量数据
...: x_test = x[-20:] # 获得测试集因变量数据
...: y_train = diabetes["target"][:-20] # 获得训练集目标变量数据
...: y_test = diabetes["target"][-20:] # 获得测试集目标变量数据
6) 训练模型并预测
In [6]: reg = linear_model.LinearRegression() # 新建线性回归模型对象
...: reg.fit(x_train, y_train) # 训练模型
...: y_pred = reg.predict(x_test) # 测试模型,预测数据
7) 查看模型评价
In [7]: print('系数:', reg.coef_) # 打印模型的系数
...: print("平均标准误差: %.2f"
...: % mean_squared_error(y_test, y_pred)) # 查看预测结果的平均误差
...: print('决定系数: %.2f' % r2_score(y_test, y_pred)) # 查看决定系数,越接近1越好
系数: [ 938.23786125]
平均标准误差: 2548.07
决定系数: 0.4713.
8) 作图
模型拟合曲线如图 1 所示。
In [8]: plt.scatter(x_test, y_test, color='black') # 作图
...: plt.plot(x_test, y_pred, color='blue', linewidth=3)
...: plt.show()
图1:模型拟合曲线
通过模型可以看出,随着体重指标的增加,病情的级数也在增加,因此可以预测某位患者接下来一年内病情将会如何发展。当然,通过多变量分析我们可以得到更好的模型。